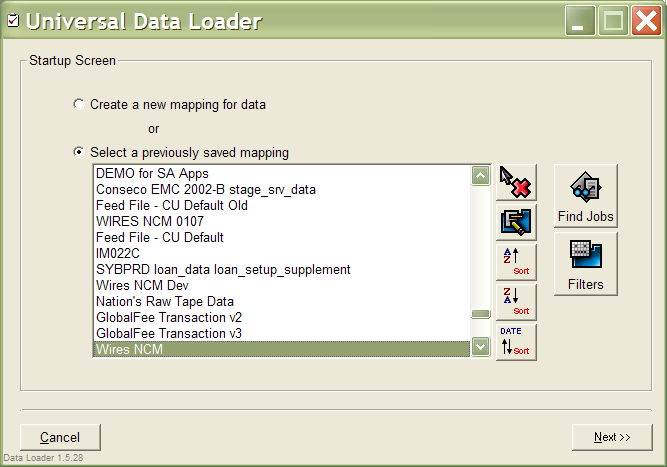
Deutsche Bank receives thousands of files every month from various partners and customers that have to be processed in a fairly speedy manner. These files come in various formats: from the old style unix files (that terminate with Ctrl-Z) to Microsoft Excel to HTML. In the past, programmers created C or C++ programs not only for each format type, but for each variation on the type. For instance, if you had two tab delimited files with different number of fields, two C programs would be written to handle them. Then a user would run these C programs from the Unix shell.
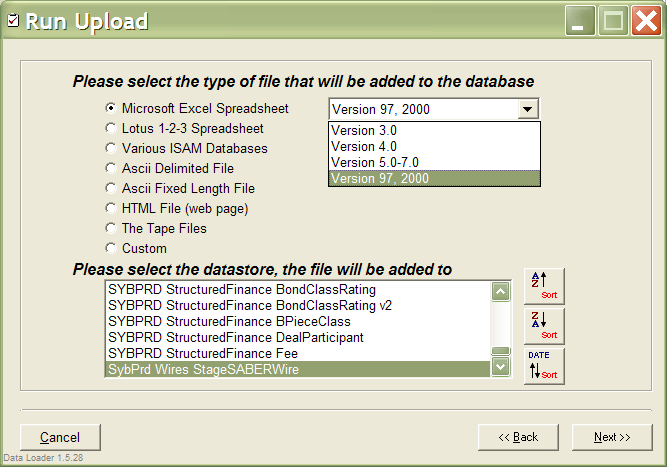
Obviously, this may have been fine in the early ninetees, but with the amount of files being received today, the situation was quickly getting out of hand. I decided to architect the system in the way that would last for many years, yet would be flexible enough to participate in other applications as a universal data loader engine. Logically speaking, there are 3 parts to processing a foreign file into your own database: 1. Read the file (Source). 2. Map the fields to your own fields 3. Upload the data to the database (Target). I built in to the program support for reading most popular file formats (Excel, Lotus 1-2-3, Microsoft Access, Tab Delimited, Comma Delimited, Whatever Delimited, Fixed Length files, dBase, FoxPro, Paradox, HTML, etc...). One thing, however, was obvious. I couldn't write filters for every conceivable file type that may show up on the bank's door. So I settled on a concept of plugins for formats not handled natively by Universal Data Loader. If a new format showed up, one could write a plugin to read it.
I also couldn't write one piece of code to upload data to multitude of servers and databases around the bank (there are literally hundreds). Bank's infrastructure is highly heterogeneous, partly a result of mergers, purchases, etc... There are Sybase servers, Microsoft SQL Servers, Oracle, etc... all with drivers of varying stability, availability, etc... For this reason, I settled on a concept of Target Plugins. Target Plugin is a piece of code that contractually provides database upload services to the Universal Data Loader engine.
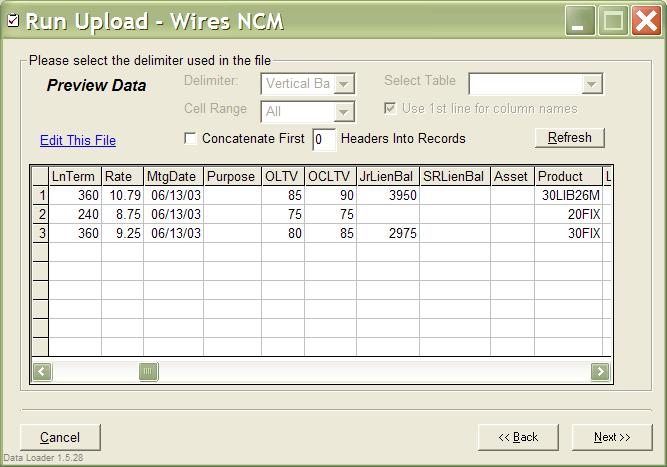
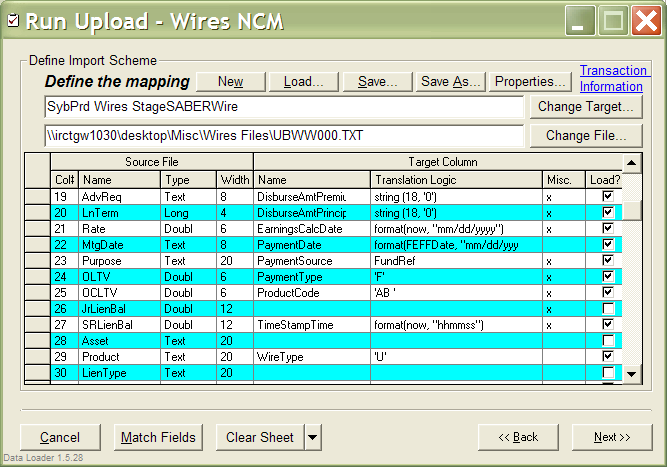
Finally, there was the all important piece of code between the Data Source and the Data Target
that allowed to map fields from the source file to the database table or stored procedure.
In addition, one could transform/translate each individual field in the process. For instance,
let's say, the source file has a date in the mm/dd/yy format, while we need it in the
yyyymmdd format. Or let's say 0 in the source file means Y in our file, while 1 means N.
The translation logic could easily handle these and much more complicated examples with
ease. In the end, we had a system like this:
Data Source/Plugin--->Field Mapping Engine--->Target Plugin--->Database Server
All the pieces of this application are well modularized and wrapped as libraries. The entire
affair was finished by placing a Wizard-based client/server interface to make it
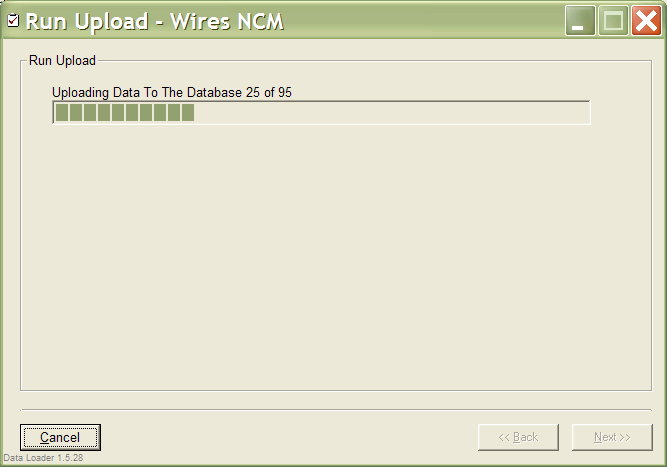
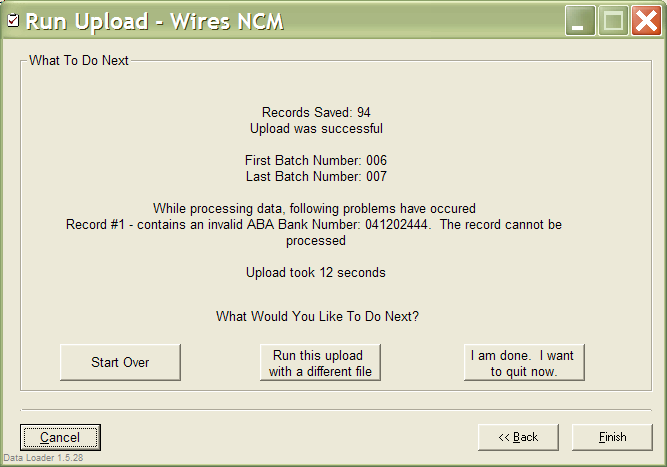
easier for users to process data.
Maintanance of hundreds of C/C++ files was a nightmare. Now it is a thing of the past. Nowadays, the files is loaded via UDL in a simple manner: user selects the file, file type, where the file should be loaded, maps the source fields to the target fields and voila. In addition, because all the pieces of UDL are wrapped as libraries, they are used within other programs around the bank as well. In addition, I provided generators that essentially wrote plugins for you. The lead for a new file format went from 2-3 man-months to one man-day.
- Language: Visual Basic 6
- Features: Interface Implementation for contract enforcement between libraries
- Data Access: ADO 2.5 for applicaions written in VB 6
- RDBMS: Sybase Adaptive Server Enterprise 12.0
- RDBMS: Microsoft SQL Server 7
- Database: Microsoft Access